
Dowiedz się, jak zintegrować praktyki odpowiedzialnej sztucznej inteligencji z przepływem pracy uczenia maszynowego za pomocą TensorFlow
TensorFlow jest zaangażowany w pomaganie w osiąganiu postępów w odpowiedzialnym rozwoju sztucznej inteligencji poprzez udostępnianie kolekcji zasobów i narzędzi społeczności ML.

Czym jest odpowiedzialna sztuczna inteligencja?
Rozwój sztucznej inteligencji stwarza nowe możliwości rozwiązywania trudnych, rzeczywistych problemów. Rodzi to również nowe pytania dotyczące najlepszego sposobu budowania systemów AI, które przynoszą korzyści wszystkim.

Zalecane najlepsze praktyki dotyczące sztucznej inteligencji
Projektowanie systemów sztucznej inteligencji powinno być zgodne z najlepszymi praktykami w zakresie tworzenia oprogramowania, przy jednoczesnym skupieniu się na człowieku
podejście do ML

Uczciwość
Ponieważ wpływ sztucznej inteligencji rośnie w różnych sektorach i społeczeństwach, niezwykle ważne jest, aby pracować nad systemami, które są sprawiedliwe i integracyjne dla wszystkich

Interpretowalność
Zrozumienie i zaufanie do systemów sztucznej inteligencji jest ważne dla zapewnienia, że działają one zgodnie z przeznaczeniem

Prywatność
Trenowanie modeli na podstawie danych wrażliwych wymaga zabezpieczeń chroniących prywatność

Bezpieczeństwo
Identyfikacja potencjalnych zagrożeń może pomóc w zapewnieniu bezpieczeństwa systemów sztucznej inteligencji
Odpowiedzialna sztuczna inteligencja w przepływie pracy ML
Odpowiedzialne praktyki AI można włączyć na każdym etapie przepływu pracy ML. Oto kilka kluczowych pytań, które należy rozważyć na każdym etapie.
Dla kogo jest mój system ML?
Sposób, w jaki rzeczywiści użytkownicy doświadczają Twojego systemu, ma zasadnicze znaczenie dla oceny rzeczywistego wpływu jego przewidywań, zaleceń i decyzji. Upewnij się, że już na wczesnym etapie procesu programowania otrzymujesz informacje od zróżnicowanej grupy użytkowników.
Czy używam reprezentatywnego zbioru danych?
Czy Twoje dane są próbkowane w sposób reprezentujący Twoich użytkowników (np. będą używane dla wszystkich grup wiekowych, ale masz dane treningowe tylko od seniorów) i rzeczywistych warunków (np. będą używane przez cały rok, ale masz tylko dane szkoleniowe) dane z lata)?
Czy w moich danych występują uprzedzenia ze świata rzeczywistego/ludzkiego?
Podstawowe uprzedzenia w danych mogą przyczynić się do powstania złożonych pętli sprzężenia zwrotnego, które wzmacniają istniejące stereotypy.
Jakich metod powinienem używać do trenowania mojego modelu?
Korzystaj z metod szkoleniowych, które zapewniają rzetelność, interpretowalność, prywatność i bezpieczeństwo w modelu.
Jak radzi sobie mój model?
Oceń wrażenia użytkownika w rzeczywistych scenariuszach w szerokim spektrum użytkowników, przypadków użycia i kontekstów użycia. Najpierw przetestuj i powtórz w dogfood, a następnie kontynuuj testy po uruchomieniu.
Czy istnieją złożone pętle sprzężenia zwrotnego?
Nawet jeśli wszystko w całym projekcie systemu jest starannie opracowane, modele oparte na uczeniu maszynowym rzadko działają ze 100% perfekcją w odniesieniu do rzeczywistych danych w czasie rzeczywistym. Kiedy problem pojawia się w działającym produkcie, zastanów się, czy jest on zgodny z istniejącymi niedogodnościami społecznymi i jaki wpływ będą miały na niego zarówno krótko-, jak i długoterminowe rozwiązania.
Odpowiedzialne narzędzia AI dla TensorFlow
Ekosystem TensorFlow zawiera zestaw narzędzi i zasobów, które pomogą rozwiązać niektóre z powyższych pytań.
Zdefiniuj problem
Skorzystaj z poniższych zasobów, aby zaprojektować modele z myślą o Odpowiedzialnej sztucznej inteligencji.

Dowiedz się więcej o procesie tworzenia sztucznej inteligencji i najważniejszych kwestiach.
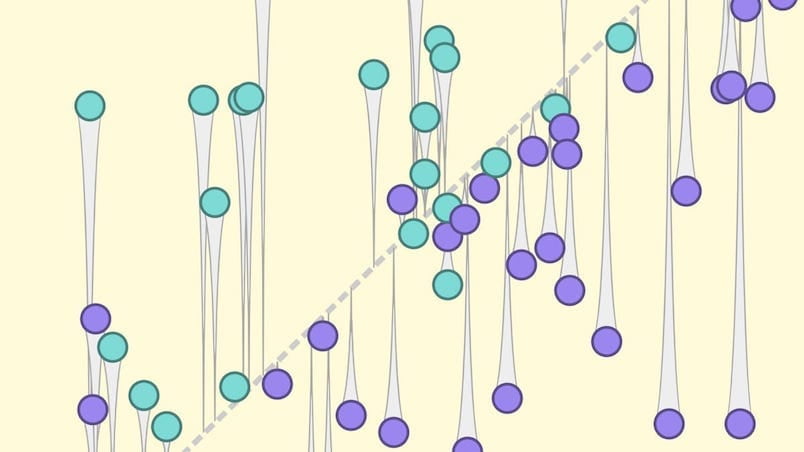
Zbadaj, za pomocą interaktywnych wizualizacji, kluczowe pytania i koncepcje w dziedzinie odpowiedzialnej sztucznej inteligencji.
Konstruowanie i przygotowywanie danych
Skorzystaj z poniższych narzędzi, aby zbadać dane pod kątem potencjalnych odchyleń.

Interaktywnie badaj swój zestaw danych, aby poprawić jakość danych i złagodzić problemy z rzetelnością i uprzedzeniami.
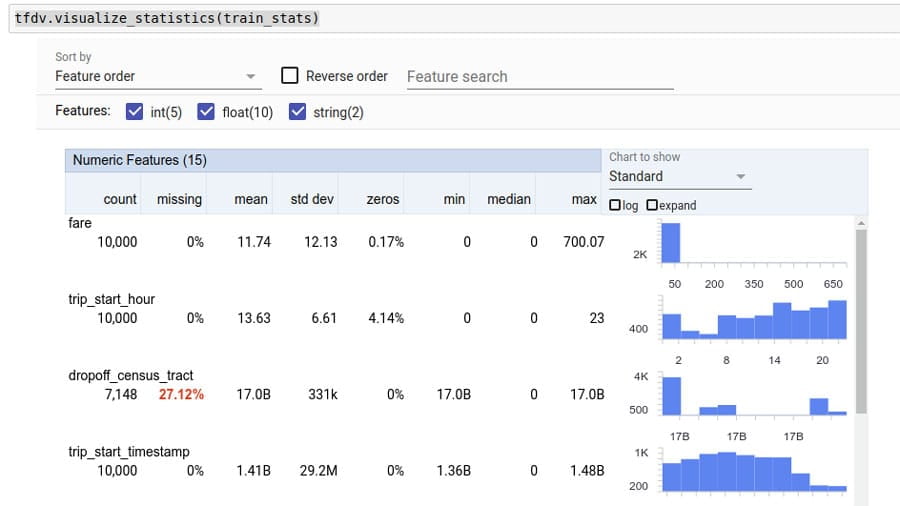
Analizuj i przekształcaj dane, aby wykrywać problemy i konstruować bardziej efektywne zestawy funkcji.


Bardziej inkluzywna skala odcieni skóry, na licencji otwartej, dzięki której gromadzenie danych i budowanie modeli będzie bardziej niezawodne i wszechstronne.
Zbuduj i wytrenuj model
Skorzystaj z poniższych narzędzi, aby trenować modele przy użyciu technik umożliwiających zachowanie prywatności, interpretowalnych i nie tylko.

Trenuj modele uczenia maszynowego, aby promować bardziej sprawiedliwe wyniki.
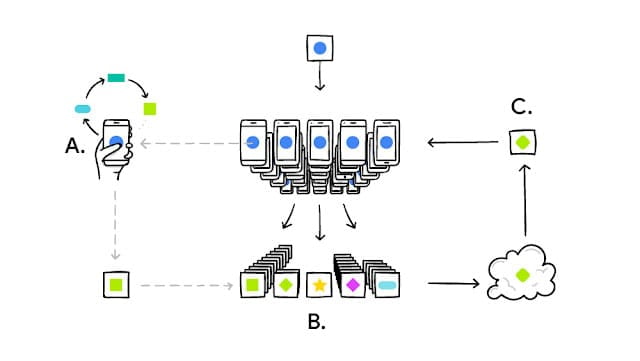
Trenuj modele uczenia maszynowego przy użyciu technik uczenia federacyjnego.
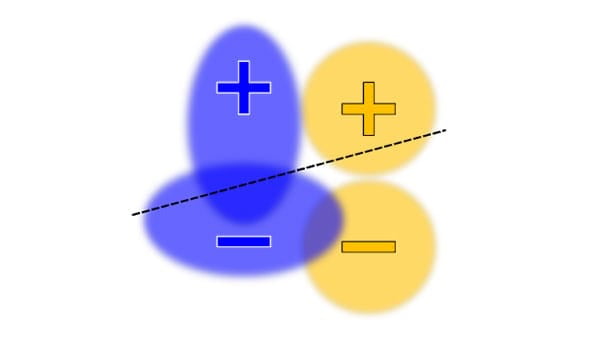
Wdrażaj elastyczne, kontrolowane i możliwe do interpretacji modele oparte na sieciach.
Oceń model
Debuguj, oceniaj i wizualizuj wydajność modelu przy użyciu następujących narzędzi.
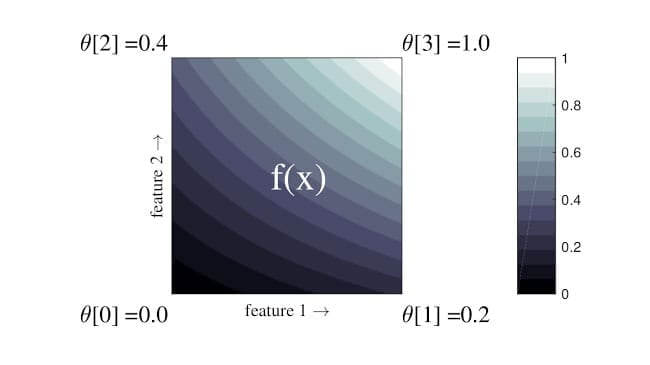
Oceniaj powszechnie identyfikowane metryki rzetelności dla klasyfikatorów binarnych i wieloklasowych.
Oceniaj modele w sposób rozproszony i przeprowadzaj obliczenia na różnych wycinkach danych.
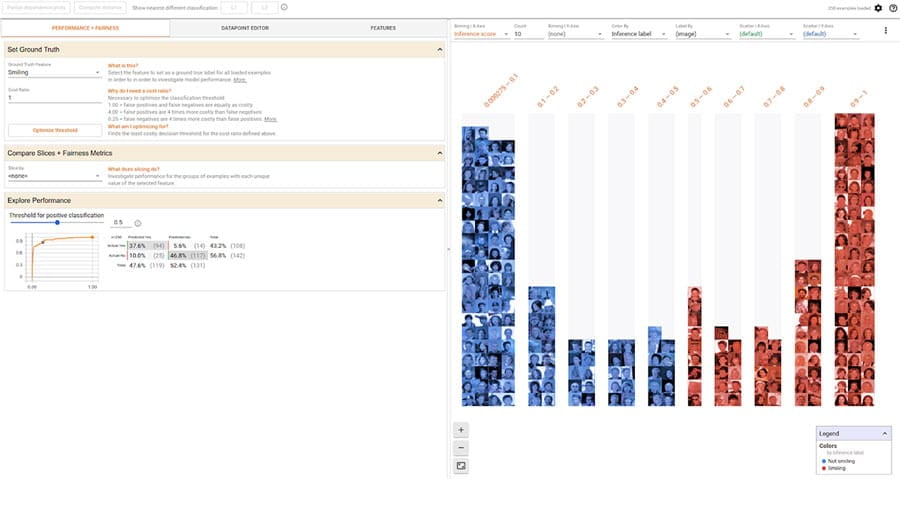
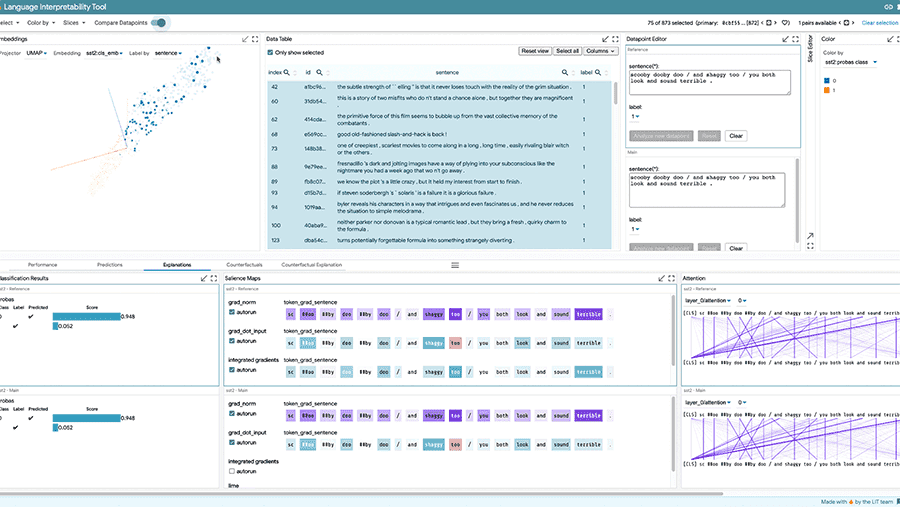
Twórz interpretowalne i integracyjne modele uczenia maszynowego.
Wdrażaj i monitoruj
Użyj następujących narzędzi do śledzenia i komunikowania się na temat kontekstu i szczegółów modelu.
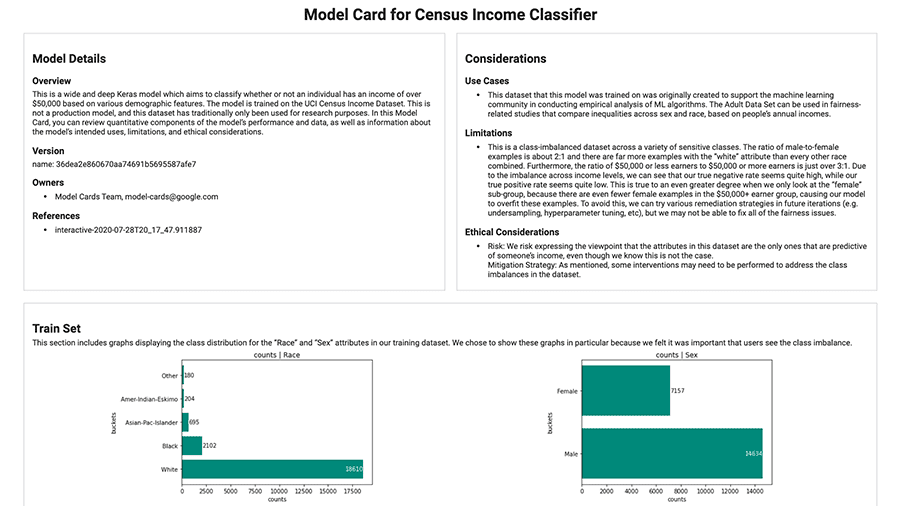
Z łatwością generuj karty modeli za pomocą zestawu narzędzi Model Card.
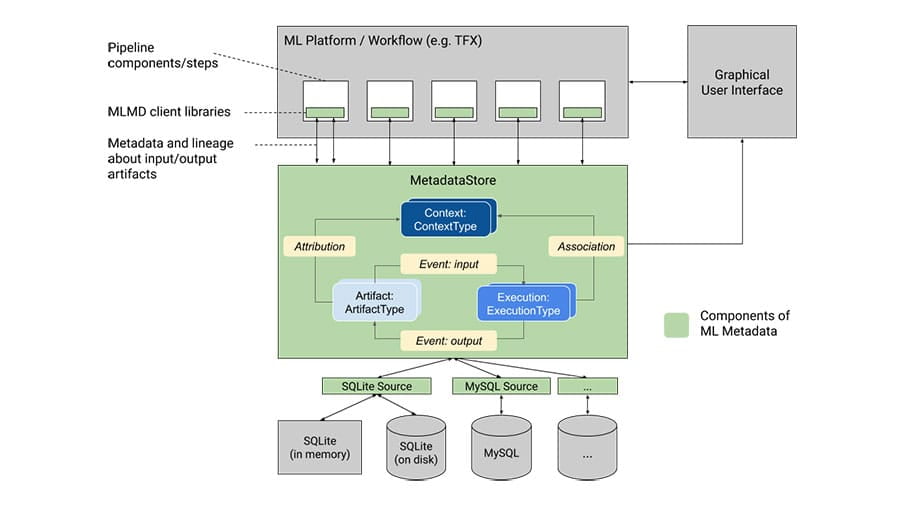
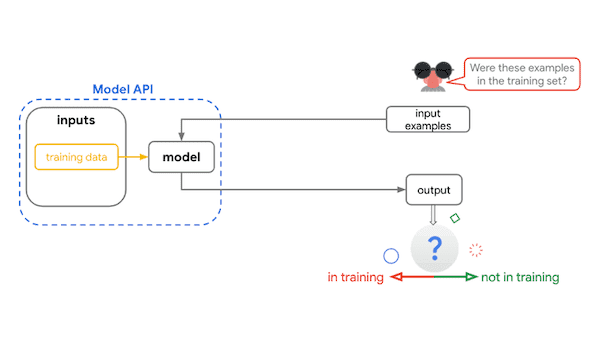
Rejestruj i pobieraj metadane powiązane z przepływami pracy programistów ML i analityków danych.

Uporządkuj najważniejsze fakty dotyczące uczenia maszynowego w uporządkowany sposób.
Zasoby społeczności
Dowiedz się, co robi społeczność i odkryj sposoby zaangażowania się.

Pomóż, aby produkty Google były bardziej otwarte i reprezentatywne dla Twojego języka, regionu i kultury.

Poprosiliśmy uczestników, aby wykorzystali TensorFlow 2.2 do zbudowania modelu lub aplikacji z myślą o zasadach Odpowiedzialnej sztucznej inteligencji. Sprawdź galerię, aby zobaczyć zwycięzców i inne niesamowite projekty.

Przedstawiamy ramy do myślenia o ML, uczciwości i prywatności.